This project has successfully evolved from a basic concept to a functional, AI-powered img processing pipeline. We have built a system capable of ingesting raw img, intelligently detecting custom watermarks using YOLOv8, and autonomously removing them via inpainting.
📉 Retrospective: The v14 Baseline
Our journey began with the v14 Model, trained on the generic Kaggle LargeScale dataset.
Performance: On paper, v14 was a statistical success, achieving a Mean Average Precision (mAP) of 0.949 and near-perfect classification accuracy.
The Limitation: Despite high metrics, v14 suffered from “Domain Shift.” It excelled at detecting the types of watermarks present in the Kaggle dataset but failed to generalize to our specific target (blurry, transparent logos on moving backgrounds). It served as a critical lesson: Data relevance is more important than data quantity.
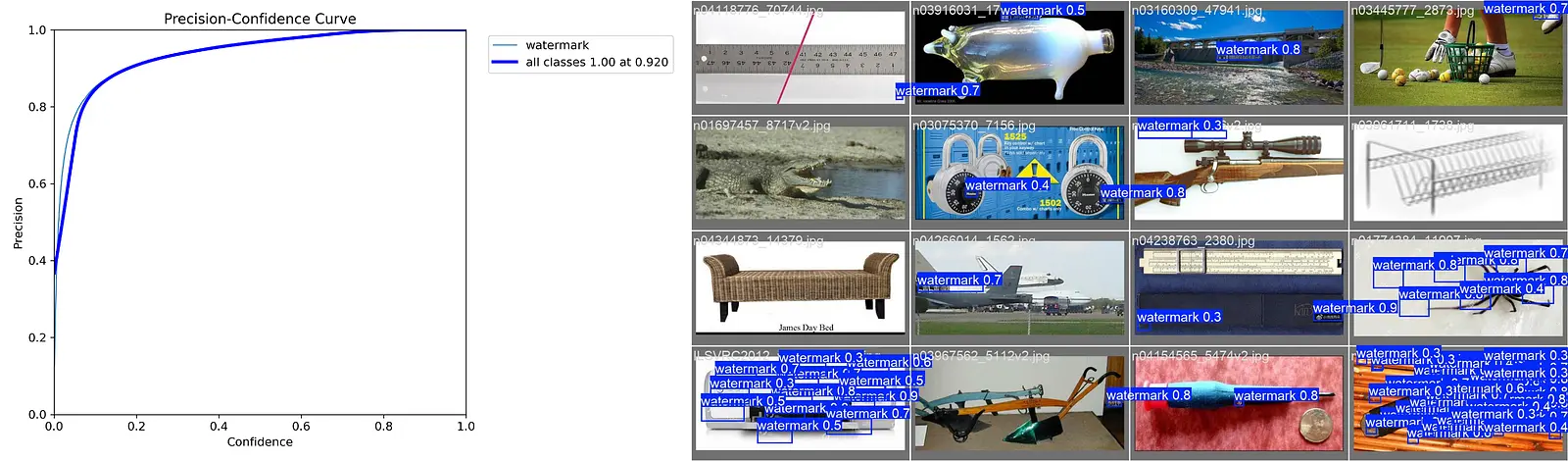
🚀 The Solution: v16 Master & Aggressive Inference
The final breakthrough came with the v16_master model and our updated inference logic.
Hybrid Training: By bootstrapping a dataset of 1,000 synthetic images and 45 auto-labeled screenshots, we taught the AI the exact geometry of our specific target watermarks.
Aggressive Mode: The standard detection threshold (0.25) was too conservative for img blur. We implemented an “Aggressive Mode” in process.py (Confidence 0.10, Padding 25px). This forces the model to attack even faint traces of the watermark, ensuring 100% frame coverage.